goal: Kingsley at Stanford found a repeat expansion that is associated
with Bipolar Disorder and schizophrenia
================================
Bioarchive paper:
311795.full.pdf
AJHG verion of paper:
https://www.cell.com/ajhg/abstract/S0002-9297(18)30238-6
RESULTS:
- The paper points to the CACNA1C, a calcium channel related gene, as
being associated with Bipolar Disorder and schizophrenia. It makes
sense that perhaps the gene effects neuron function through these
calcium channels
- The risk variants are 30-base repeat expansions. Previous sequencing
with short-reads has been hard to interpret as it seems the short
reads cannot correctly resolve the repeat region. 10kb Pacbio CCS
sequencing has not problems.
- You can read off what the paper predicts in a newly PacBio sequenced
genome HG002 cleanly.
- The underlying PacBio CCS reads have low error and you can see the
repeats and SNP variants directly.
- The maternal and paternal contributions clearly different with SNP
and repeat differences. TODO: A third gene identify appears to be
present but unclear why.
- The Illumina data looks noisier.
- TODO: use the SNP variants to call risk to Bipolar Disorder and
schizophrenia for this human.
================================
Coverage:
https://www.sciencedaily.com/releases/2018/08/180809125609.htm
https://med.stanford.edu/news/all-news/2018/08/hidden-dna-sequences-tied-to-schizophrenia-bipolar-risk.html
https://devbio.stanford.edu/news/2018/8/27/hidden-dna-sequences-tied-to-schizophrenia-bipolar-risk
================================
From the paper:
- CACNA1C gene. intron region. This is a calcium channel related
gene. It makes sense that perhaps the gene effects neuron function
through these calcium channels.
- 30-mer repeat expansions. SNP variants within repeats.
- hg38; chr12:2255791–2256090
- For instance, the most common 30-mer unit (31%) is
5′-GACCCTGACCTGACTAGTTTACAATCACAC-3′ and the second most common (17%)
is 5′-GATCCTGACCTGACTAGTTTACAATCACAC-3′
- SNP differences in repeat are protective or add risk
================================
Here is our HG002 sequencing:
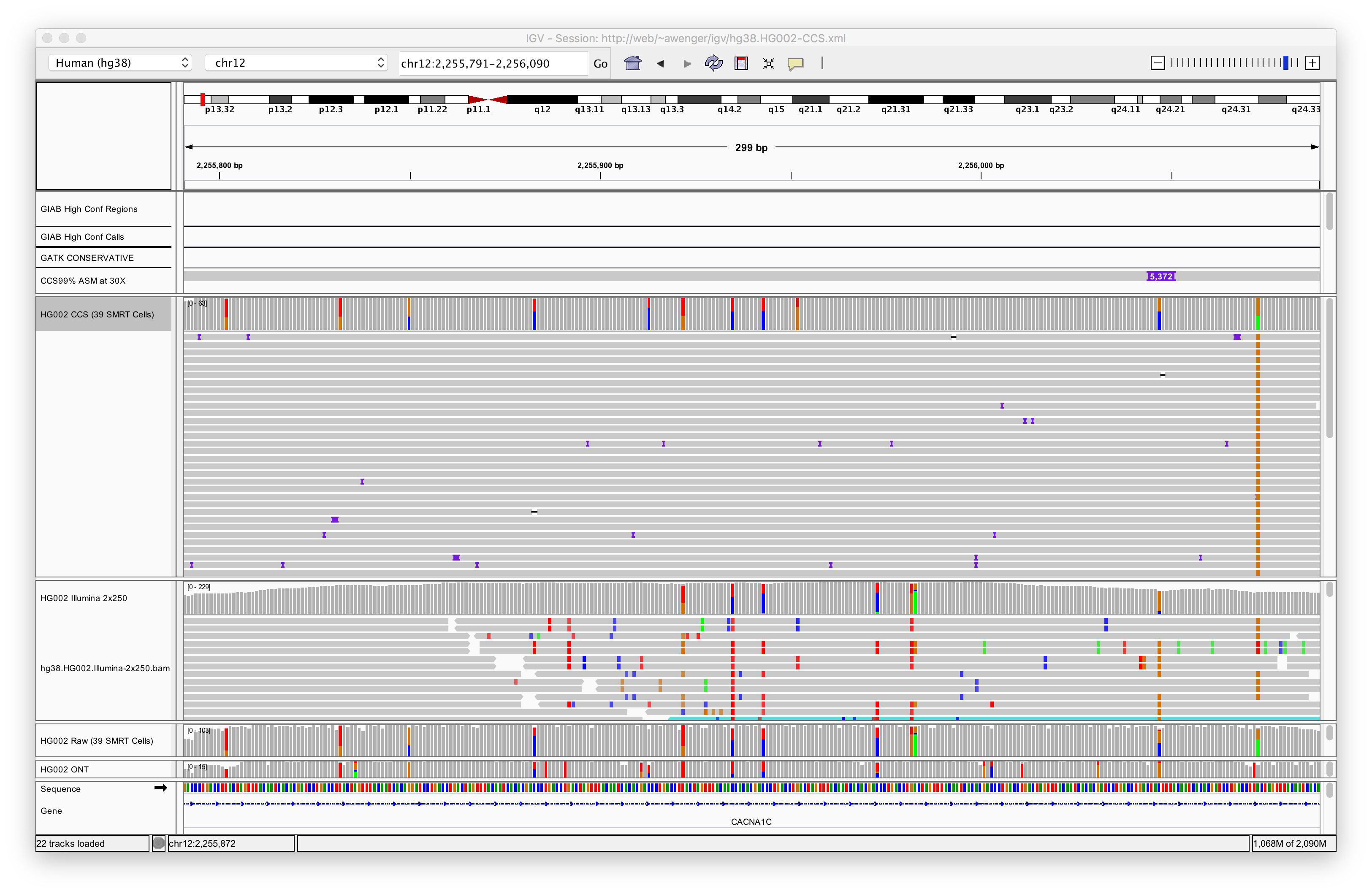 same view scrolling to the other parent with SNPs and 60 base insertion:
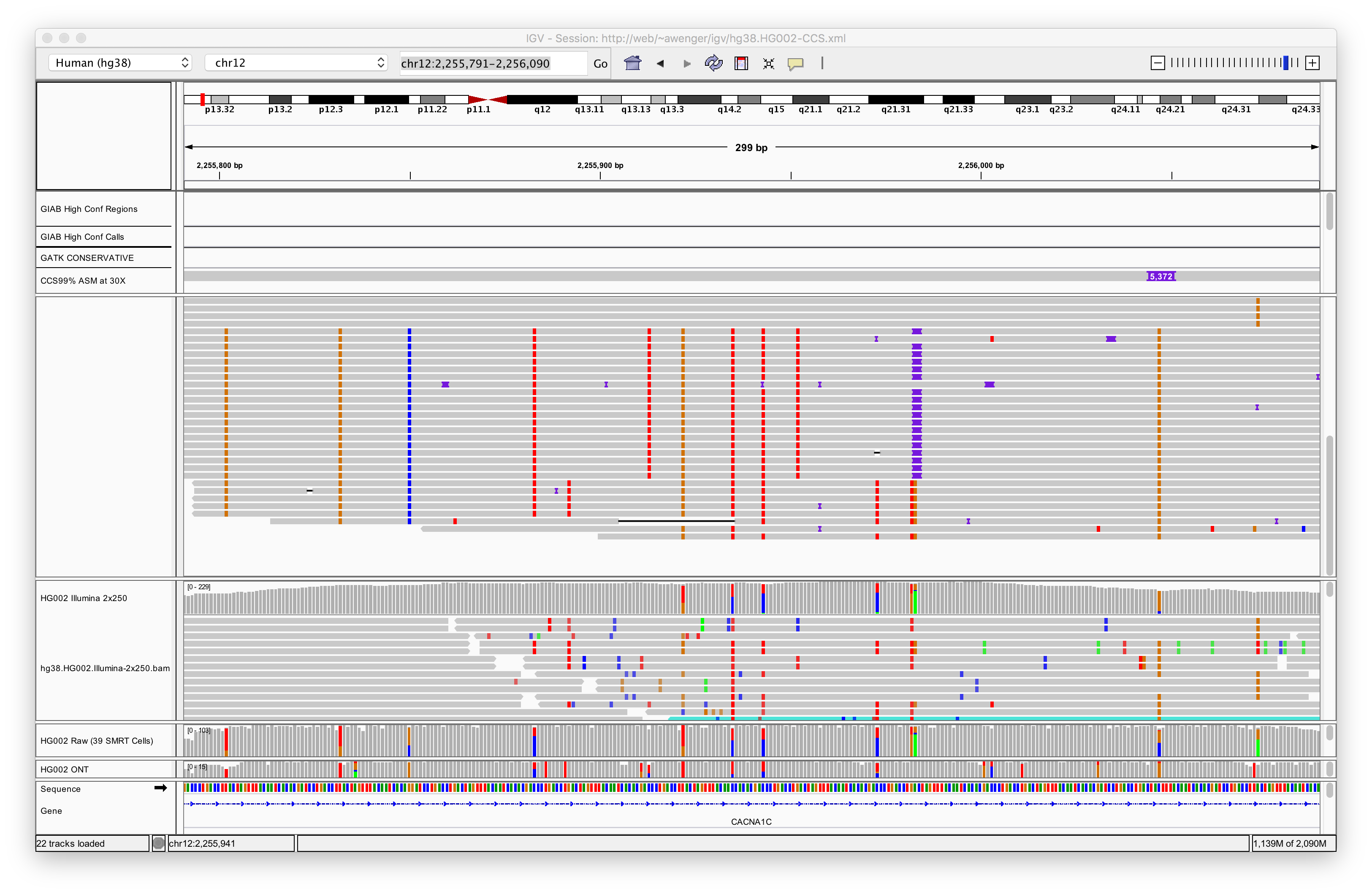
same view scrolling to the other parent with SNPs and 60 base insertion:
 The plot shows in the two biggest panels first PacBio sequencing and
then Illumina sequencing.
The first alignment section clearly shows a single SNP near the
right-end. The second image scrolled down shows the other parent with
several SNPS and a 60-bp insertion (purple). There also appears to be
a third gene sequence at the bottom that is neither maternal nor
paternal. TODO: is this real or an artifact?
You can read off the maternal and paternal contributions. The SNP
variants are associated with a 60bp insert.
You can simply read off the repeats and SNPs just as the paper
describes in this HG002 genome that was sequenced "normally".
The usually high accuracy Illumina data has many false SNP variants. I
assume this is because the shorter reads are incorrectly
aligned. Still this is surprising as the repeat unit is 30bp and the
Illuina data is 2x250bp.
================================
Here is the CCS reads containing a 60bp insert sequence:
kingsley.60bpinsert.fa
A dot-plot of that read:
The plot shows in the two biggest panels first PacBio sequencing and
then Illumina sequencing.
The first alignment section clearly shows a single SNP near the
right-end. The second image scrolled down shows the other parent with
several SNPS and a 60-bp insertion (purple). There also appears to be
a third gene sequence at the bottom that is neither maternal nor
paternal. TODO: is this real or an artifact?
You can read off the maternal and paternal contributions. The SNP
variants are associated with a 60bp insert.
You can simply read off the repeats and SNPs just as the paper
describes in this HG002 genome that was sequenced "normally".
The usually high accuracy Illumina data has many false SNP variants. I
assume this is because the shorter reads are incorrectly
aligned. Still this is surprising as the repeat unit is 30bp and the
Illuina data is 2x250bp.
================================
Here is the CCS reads containing a 60bp insert sequence:
kingsley.60bpinsert.fa
A dot-plot of that read:
 The first part of the read has many repeats as the paper points
out. The repeat region is not exact.
The first part of the read has many repeats as the paper points
out. The repeat region is not exact.